Personalized Job Recommendation System using Collaborative Filtering
A beginner’s guide to the world of Recommendation Systems and the concept of Job Recommendation System on a Kaggle dataset.
In the world that we live today, problems like unemployment and employee churn have shown tremendous increase due to the recent and ongoing pandemic situation where companies either lay-off some of their workers or people leave their jobs to be with their families. In such cases, many people are seen surfing online for finding relevant jobs based on their skills with the internet being an essential employment resource for many of today’s job seekers. This is where a Job Recommendation System plays an important role.
What is a Job Recommendation System?
Before we dive deep into the concept of Job Recommendation Systems, let us first know about Recommendation Systems in general.

A recommendation system or recommender system, is a subclass of information filtering system that seeks to predict the “rating” or “preference” a user would give to an item. The goal of a recommendation system is to generate meaningful recommendations to a collection of users for items or products that might interest them.

There are mainly two types of filtering techniques in Recommendation Systems namely: Content-based filtering and Collaborative filtering (link).
According to AI-Multiple, the industries that stand to gain from recommendation systems include: E-Commerce, Retail, Media (Netflix, Amazon Prime etc.), Banking, Telecom, etc. to name a few.

Job Recommendation Systems are therefore the Recommendation Systems that are capable of retrieving a list of job positions that satisfy a job-seeker’s desire, or a list of talent candidates that meet the requirement of a recruiter by using recommendation technology like Collaborative and Content-based filtering.
Thus, in order to build a personalized recommendation system, we required a dataset that could provide us information of the job offers and the organisation or company concerned with the job offer. Besides that, information regarding the skills linked to different job offers play an essential role in building the recommendation system.
Dataset
The dataset we hence used for building our job recommendation system was taken from Kaggle named “Jobs Data for Recommender Systems”.
In this dataset, there are 222 unique jobs acquired by different users and 155 unique skills overlap in a particular fashion to match different job descriptions of different users in the all-offers data file.

Thus, we combine the all-offers and organisations data files in order to make our base data for the recommendation system.
Our Methodology
We built a simplistic personalized job recommender system by measuring the similarity between the user skills retrieved from their profile and matching it with different job offers. For this, our approach consists of the following processes:
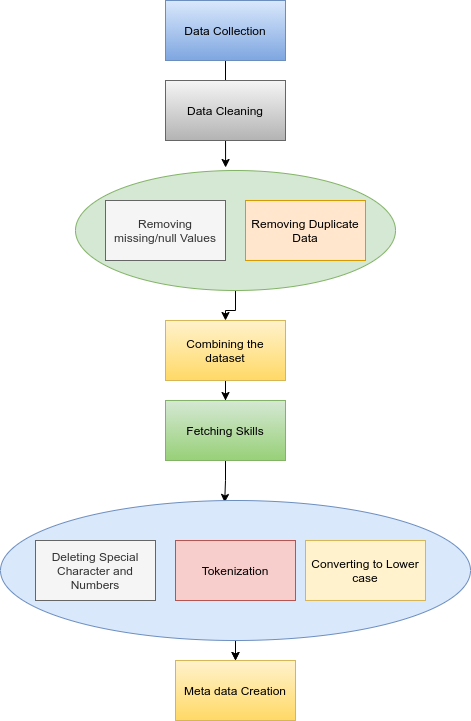
- Data Pre-processing and Meta-data creation
- Vectorization
- Measuring similarities between skill vectors
- Methods for top recommendations to users
Data Pre-processing
Since job recommendation systems deal with finding relevant jobs mainly based on one’s skill sets, therefore retrieving the skills from different jobs given is an important task.
Since the skills for each user job were stored in the form of a dictionary, therefore, in order to extract each skill for different jobs, those dictionaries were converted to strings and then a manual function to remove all special characters such as ”{”,”:”,”,”etc. were used to extract skills relevant for each job. These skills were then used as columns, and as per the availability of each skill in different jobs, the meta-data for our project was created where if the job consisted of the concerned skill, then the value in the data frame was one else in the case of the unavailability of the skill in the job the value was kept as 0.

Vectorization
Vectorization refers to the computation and generation of vectors based on the words present in a string. Here, a function called the text to vector() was used to convert the input text string to its corresponding vector such that the two vectors can be compared to understand the similarity between two text strings. This is done by importing the Counter library to count all the words in the given text.
Measuring Similarities between skill vectors
Different similarity metrics such as Cosine (Orchini), City block, and Euclidean require vectorization of the skill query input and the job-based skills for searching job options where the user skills are available and then search similar jobs based on the top match.
The different similarity measures used for generating top job recommendations include:
- Tanimoto or Jaccard Similarity
- Cosine or Orchini Similarity
- City-Block or Manhattan distance-based similarity
- Euclidean distance-based similarity
In case of distance-based similarity measures, the similarities between the user skills and job-skill vectors are inversely proportional to the distance between the skill vectors.
Top Recommendation methods
The techniques mentioned earlier and their appropriate pre-processing and vectorization were incorporated as a recommendation model and tested on user test data as a cold-start problem.
The two ways of top recommendations are: Top 5 job recommendations and Highest score based Job Recommendations. In this way, we are able to assess the performance of the models based on whether they were able to predict the user’s job accurately two different scenarios.
Results and Analysis
Based on the two types of user recommendations mentioned above, we analyze the performance of all the techniques mentioned above. The resultant jobs recommended to each new user are then checked with the job that the user is originally in as per the test dataset. If the original user job is recommended in the model result, then the model appends 1 for yes else, it appends 0 for no. This array of 0's and 1's thus received is then checked for accuracy by computing the count of 1's from the total user predictions
Among all the models made with the incorporation of different similarity metrics, the cosine similarity based job recommendation system model outperformed rest of them all. The metrics used to analyse the model performance are: accuracy, precision, recall and F1-score.

This is because cosine considers the existence of duplicate terms while computing similarity. Also, computationally, cosine has low complexity and ease over handling spare data vectors since only non-zero dimensions are considered.
Upon analyzing the result table we observe that the short-comings of some similarity measures upon recommending top 5 and highest-score based job recommendations as even upon achieving high similarity scores is due to the fact that users are seen to have different jobs than the ones recommended by the models, thus resulting in 6–10% error rates.
Future Work
Future works in the case of Personalized Job Recommendation Systems are the utilization of the user-preferred location to get job recommendations based on jobs in organizations established in nearby areas. This can be done by extracting the latitudes and longitudes of the user-preferred location and computing the euclidean distances between the latitudes and longitudes of the organization location. This filters out other jobs that fall far from the user-preferred location and gives a more accurate job recommendation.
Contributors:
Richa dwivedi (LinkedIn)(GitHub)
Project Link:
GitHub: https://github.com/drishti20075/Job-Recommender-System-using-Collaborative-Filtering
